

Advances in Edge Computing Must Innovate for Autonomous Vehicles to Realize Their Potential
Large numbers of sensors, massive amounts of data, ever-increasing computing power, real-time operation, and security concerns required for autonomous vehicles are driving the core of computation from the cloud to the edge of the network. Autonomous vehicles are constantly sensing and sending data on road conditions, location, and the surrounding vehicles.
Due to the high volume of data transfer, latency issues, and security, the current cloud computing service architecture hinders the vision of providing real-time artificial intelligence processing for driverless cars. Thus, deep learning, as the main representative of artificial intelligence, can be integrated into edge computing frameworks. Edge AI computing addresses latency-sensitive monitoring such as object tracking and detection, location-awareness, as well as privacy protection challenges faced in the cloud computing paradigm.
The real value of edge AI computing can only be realized if the collected data can be processed locally and decisions and predictions can be made in real-time with no reliance on remote resources. Latency and locality are key factors at the edge since data transport latencies and upstream service interruptions are intolerable and raise safety concerns (ISO26262) for driverless cars.
As an example, the camera sensors on a vehicle should be able to detect and recognize its surrounding environment without relying on computational resources in the cloud within 3ms and with high reliability (99.9999%). For a vehicle with 120 km/h speed, 1ms round-trip latency corresponds to 3 cm between a vehicle and a static object or 6 cm between two moving vehicles.
Currently, most existing onboard AI computing tasks for autonomous vehicle applications including object detection, segmentation, road surface tracking, sign and signal recognition are mainly relying on general-purpose hardware – CPUs, GPUs, FPGAs or generic processors. However, power consumption, speed, accuracy, memory footprint, die size, and BOM cost should all be taken into consideration for autonomous driving and embedded applications. High power consumption of GPUs magnified by the cooling load to meet the thermal constraints, can significantly degrade the driving range and fuel efficiency of the vehicle. Therefore, there is a need for cheaper, more power-efficient, and for accelerating deep learning inferences at the edge.
Custom accelerator AI chips for deep/machine learning (ML) applications with 10X faster than existing devices and consuming 1/10 the power is eminent to either dethrone or complement the traditional stand-alone chip architectures, such as GPUs, FPGAs, CPUs, and even MCUs. Depending on the AI workload and applications being on edge or data center, multiple continuums of full-custom ASICs, processing power and memory management, general-purpose program devices, and other key IP blocks may be required.
Chip and system-on-chip (SoC) standard packaging for better handling and assembly onto printed circuit boards has evolved throughout the years to the point where hundreds of package types are available today. Due to this heterogeneous architecture, selecting a package that will optimize AI accelerator chips, such as domain-specific AI-based inference ASIC, as a practical solution that suit all requirements is a bit complex and requires evaluating the effects of multiple parameters like footprint/pin-count, thermal, connectivity, tolerances, node technology, power, testability, and cost.
AI accelerator ASICs, depending on the applications, can be divided into two broad categories: (a) training and inference, and (b) inference. Training a large neural network is much more computationally intensive compared to inferencing. Most people believe that the market for deep learning inference is much bigger than the training. Commercially successful ARM-based AI core chips (Cortex) SoCs comprise the integration of a CPU cluster, neural processing units (NPUs), AI accelerators, memory, DSPs as well as ISPs.
Others AI chip manufacturers such as Apple, Samsung, Qualcomm, and HiSilicon use more or less similar key blocks. For these heterogeneous integrations, advanced packaging technology is important for minimizing latency, maximizing throughput between dies, thermal issues, and mechanical reasons like die stacks above 3D-SRAM can be considered. The integration can be in a single-chip package, or multi-chip package (MCP or SIP). Chip manufacturers may use either their own fabs or external popular foundries such as TSMC (Taiwan Semiconductor Manufacturing Corporation) or SMIC (Semiconductor Manufacturing International Corporation) using leading-edge 5nm, 7nm and 12 nm foundry processes and advanced packaging technology for AI high-performance computing (HPC).
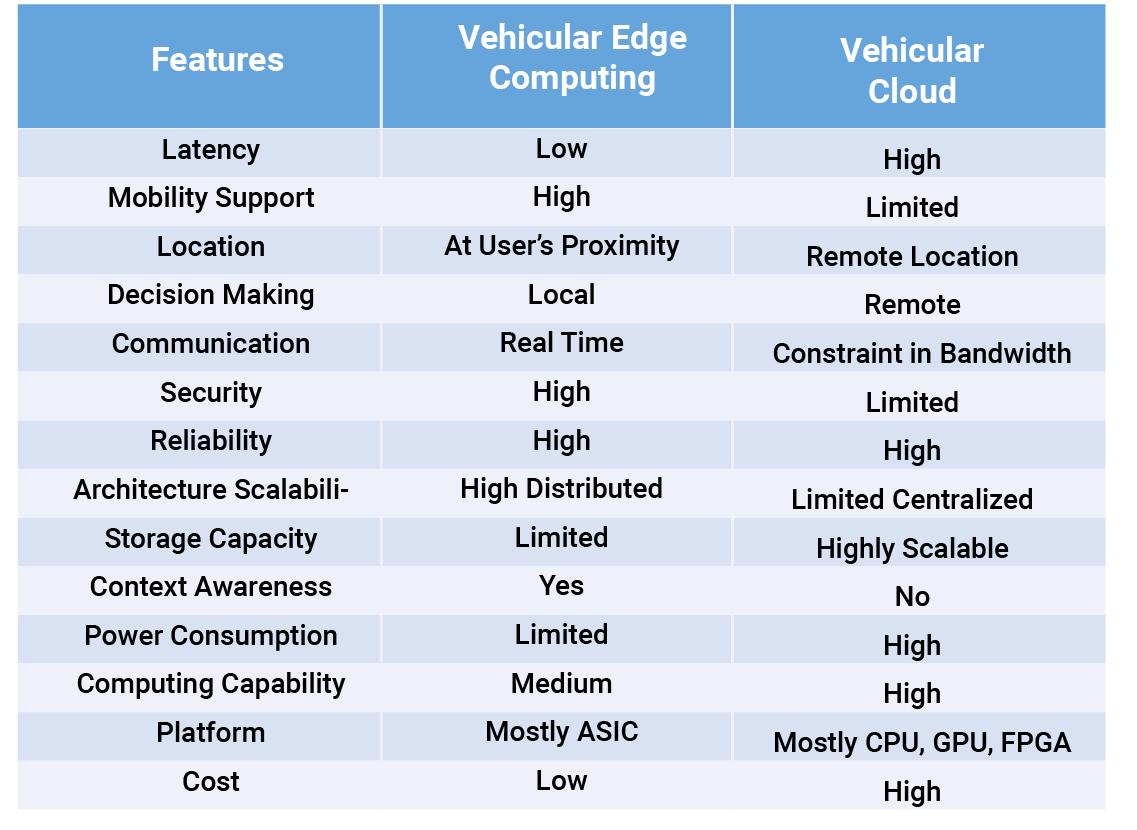
Advantages of Edge computing for AI automotive
Significant efforts have been recently spent on improving vehicle safety and efficiency. Advances in vehicular communication and 5G vehicle to everything (V2X) can now provide reliable communication links between vehicles and infrastructure networks (V2I). Edge computing is most suitable for bandwidth-intensive and latency-sensitive applications such as driverless cars where immediate action and reaction are required for safety reasons.
Autonomous driving systems are extremely complex; they tightly integrate many technologies, including sensing, localization, perception, decision making, as well as the smooth interactions with cloud platforms for high-definition (HD) map generation and data storage. These complexities impose numerous challenges for the design of autonomous driving edge computing systems.
Vehicular edge computing (VEC) systems need to process an enormous amount of data in real-time. Since VEC systems are mobile, they often have very strict energy consumption restrictions. Thus, it is imperative to deliver sufficient computing power with reasonable energy consumption, to guarantee the safety of autonomous vehicles, even at high speed.
The overarching challenge of designing an edge computing ecosystem for autonomous vehicles is to deliver real-time processing, enough computing power, reliability, scalability, cost, and security to ensure the safety and quality of the user experience of the autonomous vehicles.
Low Latency
Zero (low) latency for automotive safety is a must. Many of the self-driving car makers are envisioning that sensor data will flow up into the cloud for further data processing, deep learning, training, and analysis required for their self-driving cars. This allows automakers to collect tons of driving data and be able to use machine learning to improve AI self-driving practices and learning. Estimates suggest that sending data back-and-forth across a network would take at least 150-200ms. This is a huge amount of time, given that the car is in motion and that real-time decisions need to be made about the control of the car.
The self-driving car will be doing time-sensitive processing tasks such as lane tracking, traffic monitoring, object detection, or semantic segmentation at the local (edge) level in real-time and taking driving actions accordingly.
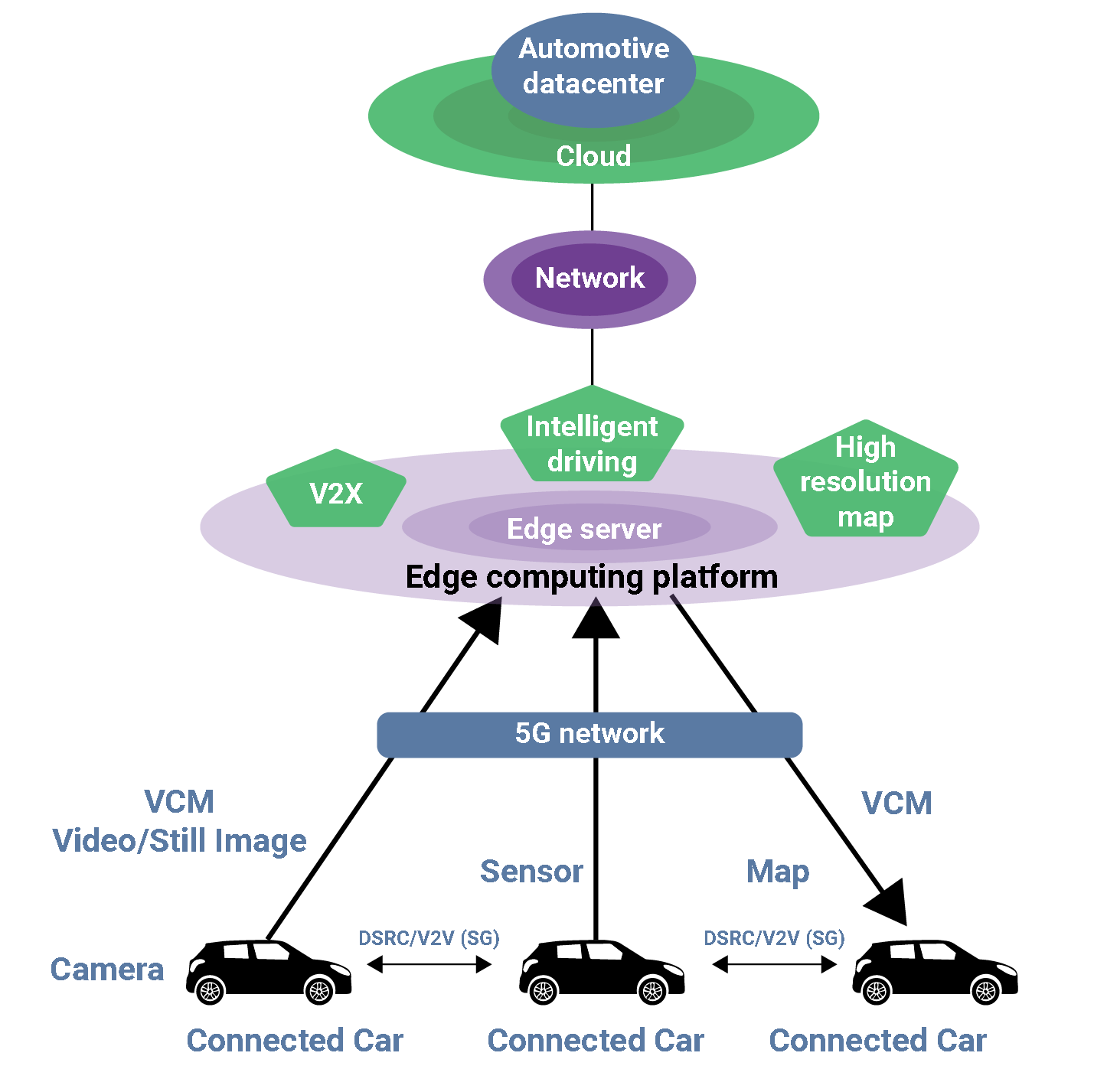
A well-designed AI self-driving and connected car will be a collaborative edge-cloud computing system, efficient video/image processing, and multi-layer distributed (5G) network – a mixture of localized and cloud processing (Figure 2).
Speed
Given the massive volume of data transmitting back-and-forth over a network, for safety reasons, much of the processing has to occur onboard the vehicle. The speed at which the vehicle needs to compute continuous data, without the need to transfer data, will help reduce latency and increase accuracy due to a reliance on connectivity and data transfer speeds.
The interdependency between humans and machines means the velocity of information transfer in real-time is essential. Using edge AI computing involves having enough localized computational processing and memory capacities to be able to ensure that the self-driving car and the AI processor can perform their needed tasks.

Reliability
The safety of autonomous cars is critical. Edge computing reduces the strain on clogged cloud networks and provides better reliability by reducing the lag between data processing and the vehicle. It didn’t take long for autonomous vehicle manufacturers to realize the limitations of the cloud. While the cloud is a necessity, autonomous cars require a more decentralized approach.
With so many edge computing vehicles connected to the network, data can be rerouted through multiple pathways to ensure vehicles retain access to the information they need. Effectively incorporating Internet of Vehicles (IoV) and edge computing into a comprehensive distributed edge architecture providing unparalleled reliability and availability.
Security
The ultimate challenge of designing an edge computing ecosystem for autonomous vehicles is to deliver enough computing power, redundancy, and security to guarantee the safety of autonomous vehicles. Thus, protecting autonomous driving edge computing systems against attacks at different layers of the sensing and computing stack is of paramount concern.
Security of autonomous vehicles should cover different layers of the autonomous driving edge computing stack. These securities include sensor security, operating system security, control system security, and communication security.
Scalability
While the cloud is a necessity for certain tasks, autonomous cars require a more decentralized approach. Decentralized architecture reduces network latency during the data transfer process as data no longer has to traverse across the network to the cloud for immediate processing. AI vehicles are being equipped with more onboard computing power than in the past and can perform more tasks on their own. with higher predictability and less latency.
Cost
The increasing number of roadside units (RSUs) equipped with powerful local AI processors can help lower energy consumption, maintenance, and operational costs as well as the associated high bandwidth cost of transferring data to the cloud. Meanwhile, one of the key drivers making edge computing a more viable reality today is that the cost of computing and sensors continues to plunge.
AI Automotive Processor Technology
The automotive industry is undergoing key technological transformations, advancing towards higher automation levels. Intelligent driving requires more efficient and powerful AI processors. According to Horizon Robotics’ summary of OEM demands, a higher level of automated driving requires more orders of magnitude tera operations per second (TOPS), namely, 2 TOPS for L2 autonomy, 24 TOPS for L3, 320 TOPS for L4, and 4,000+TOPS for L5.
Automotive processors typically fall into three broad categories:
- CPU and GPU-based processors: tend to have good flexibility but generally consume more power
- FPGAs requires less computational resources, but are more costly and limited programmability compared to GPUs
- ASICs: usually with a custom design, are more efficient in terms of performance, cost, and power consumption
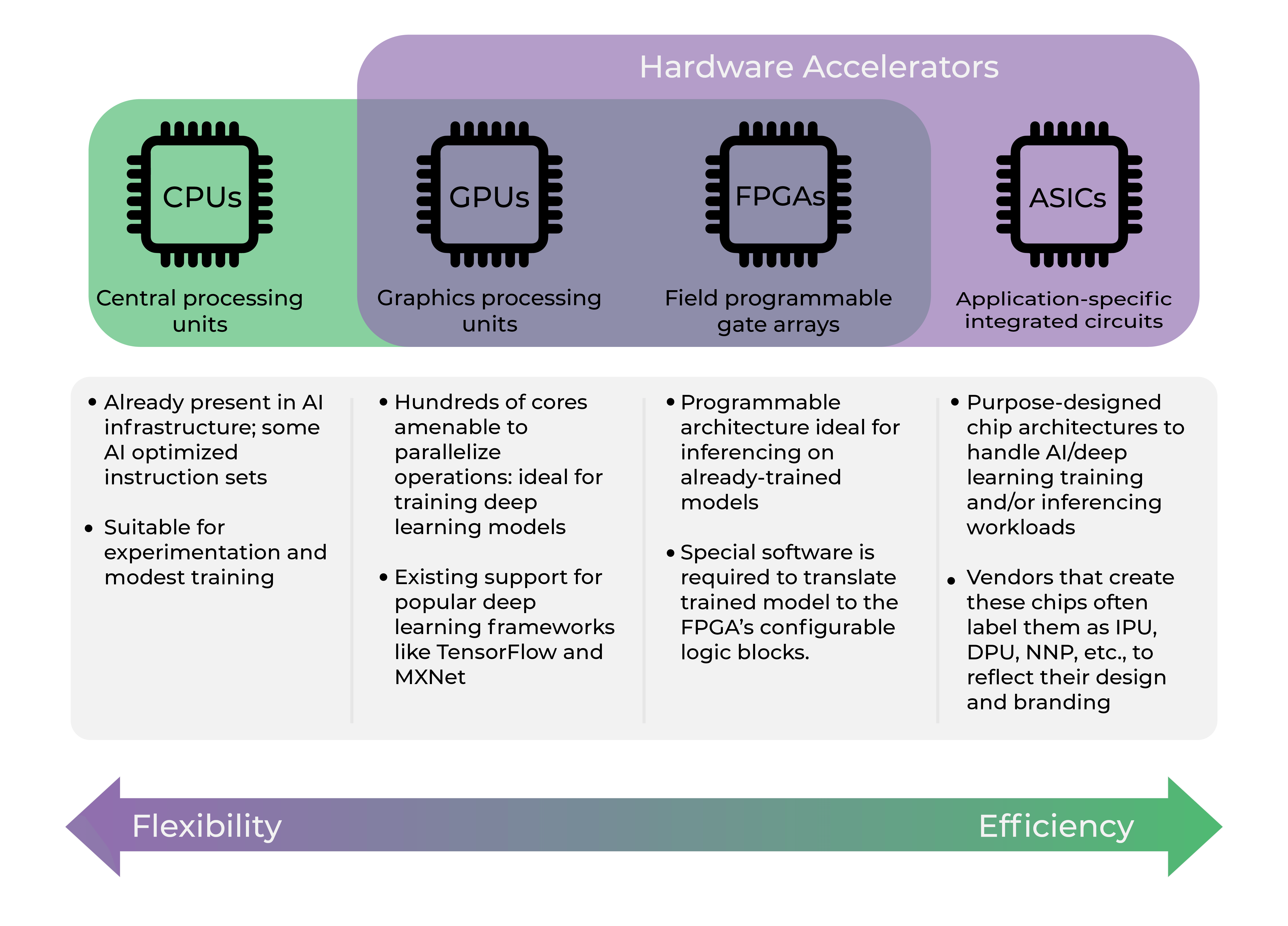
Conventional CPUs and GPUs are struggling to meet the increasing demands of high computing requirements of L4 and L5 autonomous driving levels where FPGAs/ASICs are both outperforming CPUs/GPUs. Autonomous vehicles will need enough computing power to become a “data center on wheels”. Taking the complexity of automotive applications into consideration, computing power alone is not enough. The energy efficiency, performance, and cost-effectiveness of AI automotive processors should also be taken into consideration. Full-custom ASICs are by far superior to GPUs/FPGAs in terms of lower power consumption, performance, and cost. That is why the integration of AI-specific ASIC accelerators in autonomous driving computing platforms is booming.
High-Performing Accelerator Chips
The inference accelerator chips of Gyrfalcon Technology, Inc (GTI) have a Convolutional Neural Network Domain-Specific Architecture (CNN-DSA) with a dedicated Matrix Processing Engine (MPE) and an efficient AI Processing in Memory (APiM) technology. As an example, GTI’s LightSpeeur 2803S provides a power efficiency performance of 24 TOPS/Watt with all CNN processing done in the internal memory instead of outside DRAM. It can classify 448×448 RGB image inputs at more than 16.8TOPS with a peak power consumption of less than 700mW and with an accuracy comparable to the VGG benchmark. Gyrfalcon’s CNN- DSA accelerators are reconfigurable to support CNN model coefficients of various layer sizes and layer types.
For more computationally-intensive edge computing applications such as in driverless-car AI platforms, GTI’s PCIe- based AI accelerator cards using 16x 2803S chips delivering 270 TOPS and 9.9 TOPS/W power efficiency can be used for Level 4 AI auto performance demand. Using 4x GTI 2803S PCIe cards (64 chips) can provide the top performance of 1080 TOPS for L5 AI auto performance and beyond.
GTI’s AI-based chips have a flexible and scalable architecture and can be easily arranged in either parallel or cascades for any given performance/model size application. Cascading capability provides flexibility and reduces the host workload. Cascading enables support for larger and more complex models (i.e. ResNet-101, ResNet-152, … (Figure 5).
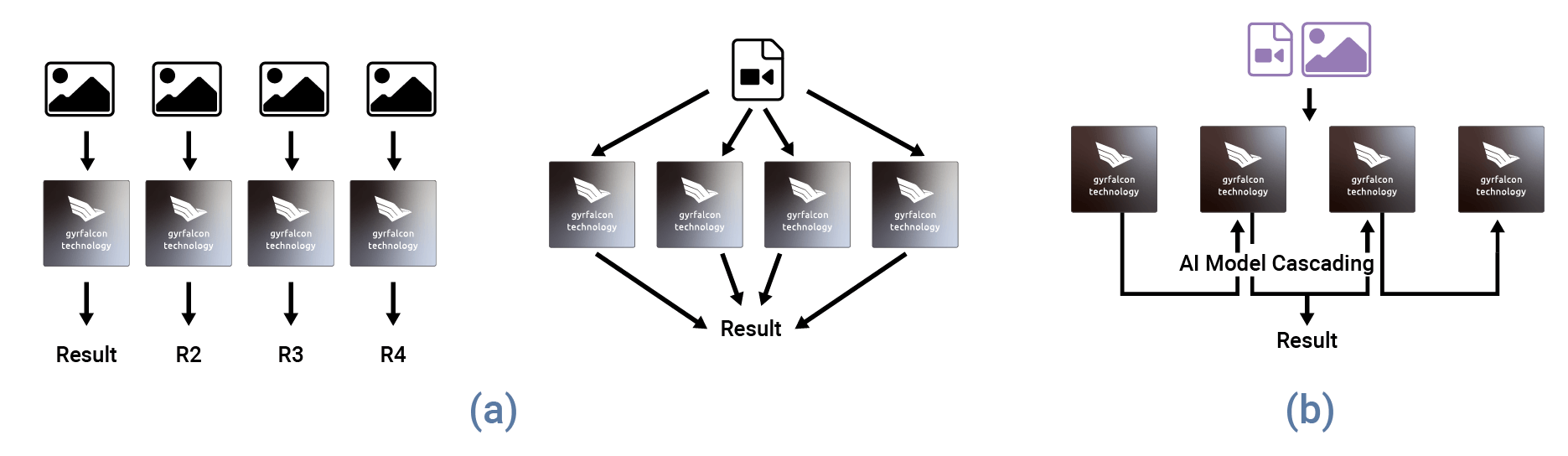
GTI’s AI-based architecture is “silicon-proven” standalone accelerator technology that can be used with any type of sensor output, such as visual, audio, and other forms of data. This can include high data rates from machine learning cameras and high-resolution LiDAR as well as low data rates from RADAR and ultrasonic sensors.




Comments are closed.