

The growing digitalization of our society has made our lives connected and, in many aspects, easier. But the digital revolution also implies that the total amount of data processed in the world is doubling every two years or so. Electronic devices such as mobile phones, laptops, satellites, servers or self-driving vehicles must cope with twice as much data, at higher speeds. Traditional signaling methods for transmission of information between chips in an electronic device are at the end of their lifetimes. Moore’s Law, the golden rule that has dominated much of the electronics industry in the last decades, is reaching its limits as well. The time is ripe for entirely novel means of communicating data; methods that allow faster communication of information at radically lower power.
Born out of this necessity, Kandou Bus has created a new signaling paradigm, called Chord™ signaling. Based on 40+ years of cumulative research, Chord signaling transforms incoming bit streams onto well-chosen patterns and superimposes them on multiple wires. At the receiver, a network of comparators detects the individual bits transmitted on the wires. Operationally, each such comparator compares the average of the values on a subset of the wires against the average of wire values on another subset (Figure 1).
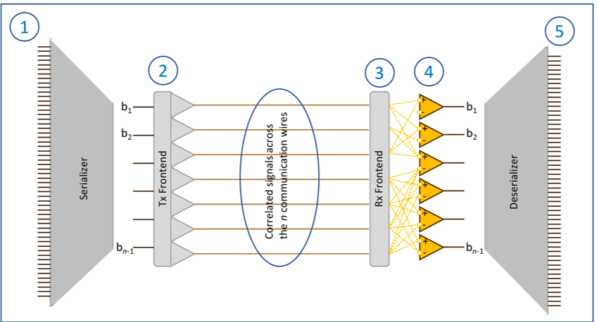
The key to the efficiency of Chord signaling is the fact that by choosing the set of transmitted values and the comparators judiciously, the sampled values become binary, even though the transmitted values are not. Therefore, Chord signaling increases the throughput per wire without paying the price of reduced margins like other signaling methods such as PAM-4. There is a small price to pay for this efficiency, however: the number of transmitted bits is always one fewer than the number of wires. Hence, the “pin-efficiency” (effective number of bits transmitted per wire) is (n-1)/n when there are n wires. While this is slightly smaller than PAM-4, which has a pin-efficiency of 1, the resilience of Chord signaling to severe noise types such as Inter-symbol-Interference, crosstalk, and EMI make for much higher margins than other signaling methods based on a pair of wires.
Examples of Chord signaling methods abound for any given number of wires. Two such examples are ENRZ, transmitting 3 bits on 4 wires, and CNRZ-5, transmitting 5 bits on 6 wires. Both of these techniques have been standardized by JEDEC (JESD247). Additionally, ENRZ has been standardized by the OIF (CEI-56G-LR-ENRZ) for communication on long reach electrical channels. ENRZ has been developed specifically for long reach links, whereas CNRZ-5 shines on ultra-short reach links, like the ones encountered in multi-chip modules (MCMs).
Ultra-Short-Reach (USR) SerDes for Disaggregation of SoCs in an MCM
Today’s systems-on-chips (SoCs) combine a large number of functions and intellectual property cores (IPs) on a single die. Process miniaturization, the main premise of Moore’s Law, has been instrumental in this regard. However, massive integration of function is slowing down, partly because Moore’s Law is coming to an end, and in a larger part because of the difficulty of verifying the inter-operation of the multitude of IPs on the same die, as well as the reduced yield of large dies in advanced semiconductor processes (Figure 2).
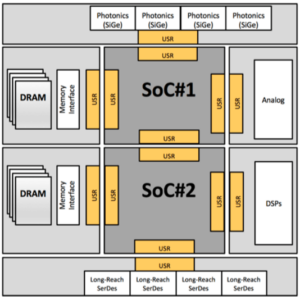
Because of these reasons, the industry is reversing the trend of the last two decades and is moving towards a disaggregation of large SoCs. Instead of integrating various IPs onto the same die, each IP (or a small set of IPs) is implemented on its own dedicated die, also called a “chiplet.” The chiplets may not all be in the same semiconductor process. Rather, the process can be judiciously chosen to obtain the best performance out of the chiplet. The shared package containing all these chiplets should be economical to build and manufacture (Figure 3).
Moreover, to offer system designers maximum flexibility, it should be possible to have close to no constraints on the placement of such chiplets inside the shared package. In addition, the links connecting such chiplets should have an extremely high bandwidth, extremely low power, and exceedingly low latency (comparable to on-chip links).
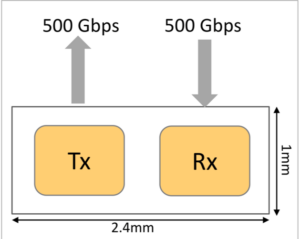
Kandou’s Glasswing family of USR SerDes has been designed with all these constraints in mind. In fact, CNRZ-5, the Chord signaling scheme transmitting 5 bits on 6 correlated wires has been specifically designed for this application. The 16nm version of the IP delivers more than 200 Gbps of bi-directional bandwidth per mm of die-edge, at phenomenally low power. In addition to Chord signaling, a number of innovations have been employed in the design of this IP, including new circuits and architectures for clocking, signal integrity, and the entire transmission chain.
One of the first application examples of Glasswing is the separation of the I/O sub-system of a SoC from the main die. A separate SerDes chiplet, which contains one or more instantiations of a long-reach SerDes (e.g., CEI-56G-LR-PAM-4), together with the physical coding sublayer (PCS) and other functions [such as the forward error correction (FEC)]. The separate SerDes chiplet has a number of advantages: it leads to a better yield of the SoC die, it reduces time-to-market for the SoC development, it leads to faster process migration for new versions of the SoC. Moreover, since the chiplet can be placed on top of the package bumps, it vastly reduces the in-package loss of long reach SerDes. Additionally, since the chiplet is connected to the SoC via a SerDes, the shared package can be a multi-chip module (MCM), which is much more economical than competing packaging technologies.

Disaggregation of SoCs is a direct consequence of the end of Moore’s Law. However, Gordon Moore foresaw this development in his seminal paper which forms the basis of his famous law:
“It may prove to be more economical to build large systems out of smaller functions, which are separately packaged and interconnected. The availability of large functions, combined with functional design and construction, should allow the manufacturer of large systems to design and construct a considerable variety of equipment both rapidly and economically.”
We conquer wholeheartedly with Moore’s foresight! ~ A. Shokrollahi
About the Author
 Amin Shokrollahi, Founder and CEO, Kandou Bus, has been at the forefront of research in information communication for the last 20 years. A Fellow of IEEE, he has published 130+ papers and has 120+ granted and filed patents in the area of information transmission.
Amin Shokrollahi, Founder and CEO, Kandou Bus, has been at the forefront of research in information communication for the last 20 years. A Fellow of IEEE, he has published 130+ papers and has 120+ granted and filed patents in the area of information transmission.
Amin was the Chief Scientist of Digital Fountain, a company specializing in the transmission of data on unreliable networks, which was acquired by Qualcomm, Inc., in 2009. Amin is also the inventor of Raptor codes, a class of codes that have been standardized by 3GPP, DVB, IPTV, and other standards bodies. He is the co-recipient of the 2002 IEEE Information Theory Society best paper award, the co-recipient of the 2008 IEEE Eric E. Sumner Award, and the recipient of the 2008 joint IEEE information theory and communication theory society best paper award. In 2012, Amin was awarded the IEEE Richard W. Hamming Medal, one of the most prestigious awards of the IEEE.










